Language-Agnostic Abstraction
Unifies language-specific dependency patterns, package managers, and test runners under one interface.
RAT is a language-agnostic framework for automated repository-level environment configuration. It combines semantic initialization, dual-mode planning, specialized tools, and robust sandboxing to improve executability across heterogeneous real-world repositories.
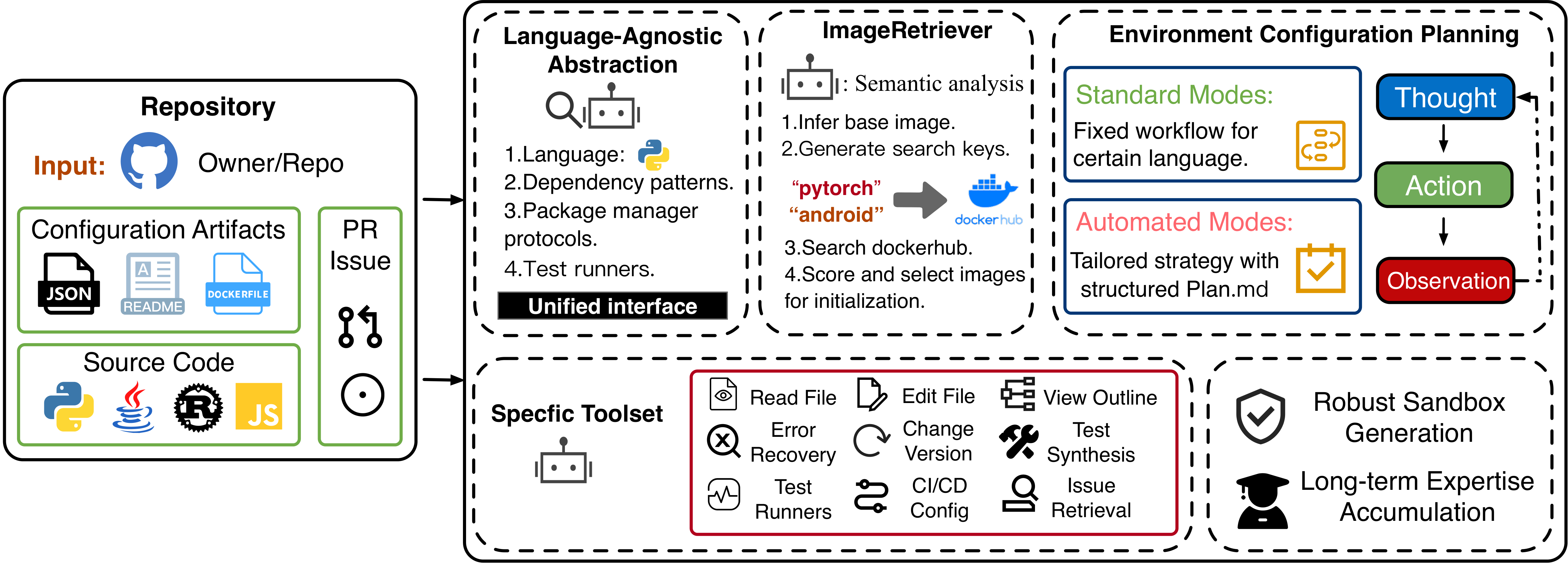
Unifies language-specific dependency patterns, package managers, and test runners under one interface.
Semantically analyzes repo artifacts, infers base images, and scores candidate images from Docker Hub.
Supports Standard Plan Mode and Automated Plan Mode with a structured memory.
Includes read/edit/outline/search/issue retrieval/version switch/error recovery/CI parse/test runners.
Builds tailored Docker environments and runs pre-flight validation before agent execution.
Serializes historical trajectory knowledge to improve future configuration precision.
RATBench is a large-scale benchmark targeting distribution diversity, language diversity, and availability diversity, with executability-driven validation.
| Benchmark | # Repos | Langs. | Stratified | Auto-Collect | Exec-Verified | Difficulty Levels |
|---|---|---|---|---|---|---|
| RATBench | 2,000+ | P, J, R, JS/TS | Yes | Yes | Yes | Yes |
| EnvBench | 994 | P, J, K | No | Yes | No | No |
| Repo2Run | 420 | P | No | Yes | Yes | No |
| ExecutionAgent | 50 | 14 Langs | No | No | Yes | No |
| Beyond Pip | 40 | P | No | No | Yes | No |
P: Python, J: Java, K: Kotlin, R: Rust, JS/TS: JavaScript/TypeScript.
We define ESSR with scenario-specific handling. For Python, it refines the metric to account for pre-existing repository issues.
Here, N_pass is the number of tests that pass in the configured environment; N is the total number of repository tests; and N_verified is the subset of tests verified as inherently valid (excluding pre-existing broken tests).
For Java / Rust / JS/TS, success is defined by deterministic build/installation command completion without errors.
| Framework | LLM | Python | Java | Rust | JS/TS |
|---|---|---|---|---|---|
| pipreqs | None | 35.8 | / | / | / |
| Zero-shot | DeepSeek-V3 | 15.2 | 0.0 | 0.0 | 7.3 |
| SWE-agent | DeepSeek-V3 | 15.5 | 29.3 | 56.7 | 51.8 |
| Installamatic | DeepSeek-V3 | 6.7 | / | / | / |
| Repo2Run | DeepSeek-V3 | 44.8 | / | / | / |
| RAT | DeepSeek-V3 | 63.2 | 41.3 | 98.7 | 68.7 |
RAT consistently outperforms baseline methods across languages. On Python, RAT reaches 63.2% ESSR (vs. 35.8% for pipreqs), and shows a 29.6% average gain over SWE-agent across evaluated language columns.
| Levels | ESSR (%) | Tokens (K) | Latency (min) |
|---|---|---|---|
| S1 | 50.5 | 451.3 | 41.6 |
| S2 | 69.5 | 455.2 | 59.4 |
| S3 | 92.0 | 122.2 | 14.4 |
Strong S2 performance indicates RAT can leverage project files and documentation even without containerization scripts. S3 results show RAT can infer entry points and build effective smoke tests in underspecified settings.
If you find RAT useful, please site:
@misc{huang2026ratrunanythingfullyautomated,
title={RAT: RunAnyThing via Fully Automated Environment Configuration},
author={Renhong Huang and Dongdong Hua and Yifei Sun and Sitao Ding and Hanyang Yuan and Daixin Wang and Yang Yang},
year={2026},
eprint={2604.23190},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2604.23190},
}